机译译文质量评估
对机器翻译的译文结果进行评估是一个经典问题,之前我们用COMET搭建了一个评分系统,但是没过多久大模型就出来,UNBABEL也很快更新了他的QE LLM。
目前有两个版本:
根据WMT 2023的比赛,在中英这个维度上,成绩还是非常不错。
Demo系统
- 译文评分系统 Unbable QI

- 译文比较系统
初步使用
用打分系统做了一个测试。
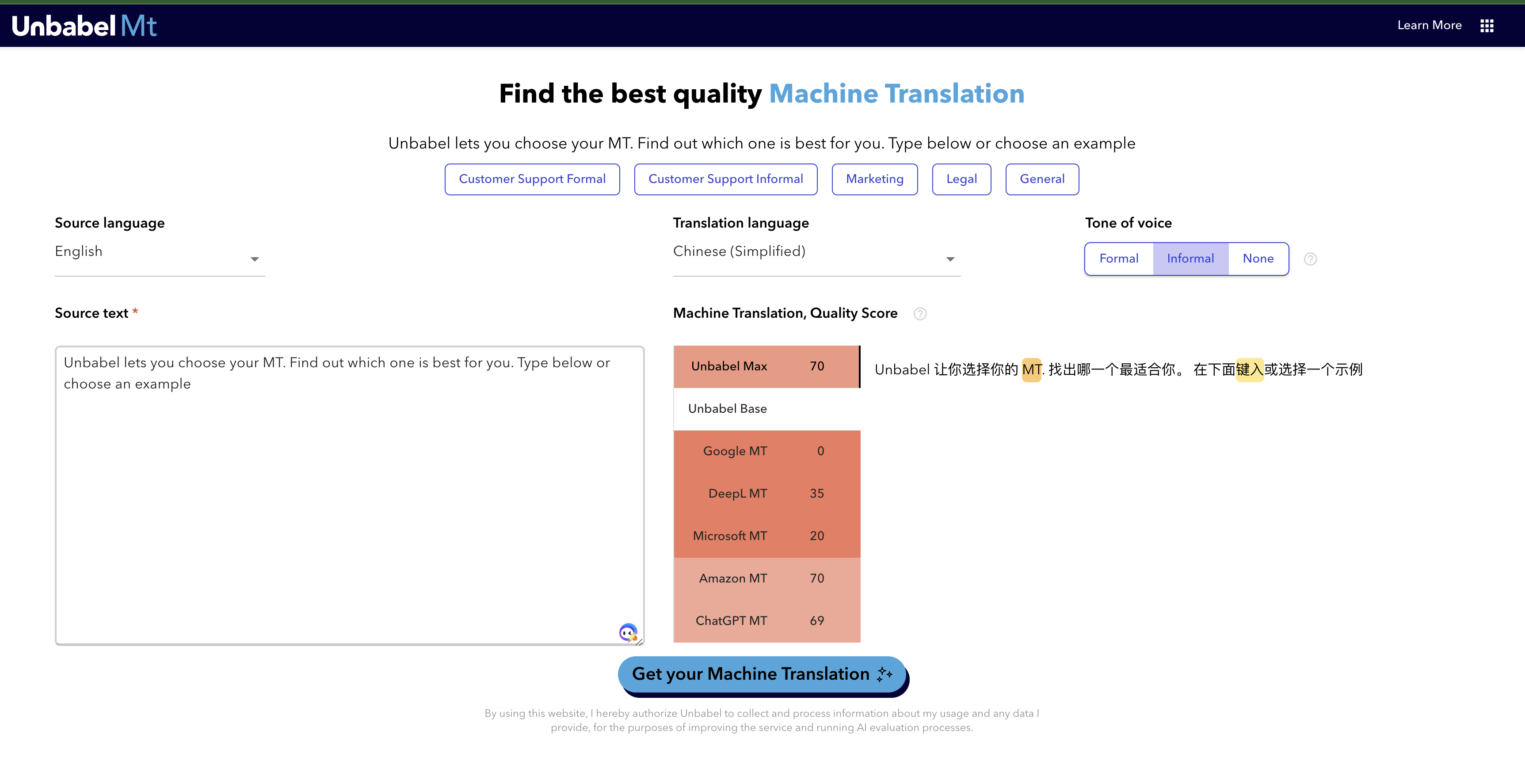
原文:Unbabel lets you choose your MT. Find out which one is best for you. Type below or choose an example
得分最高的结果:
ChatGPT的效果:
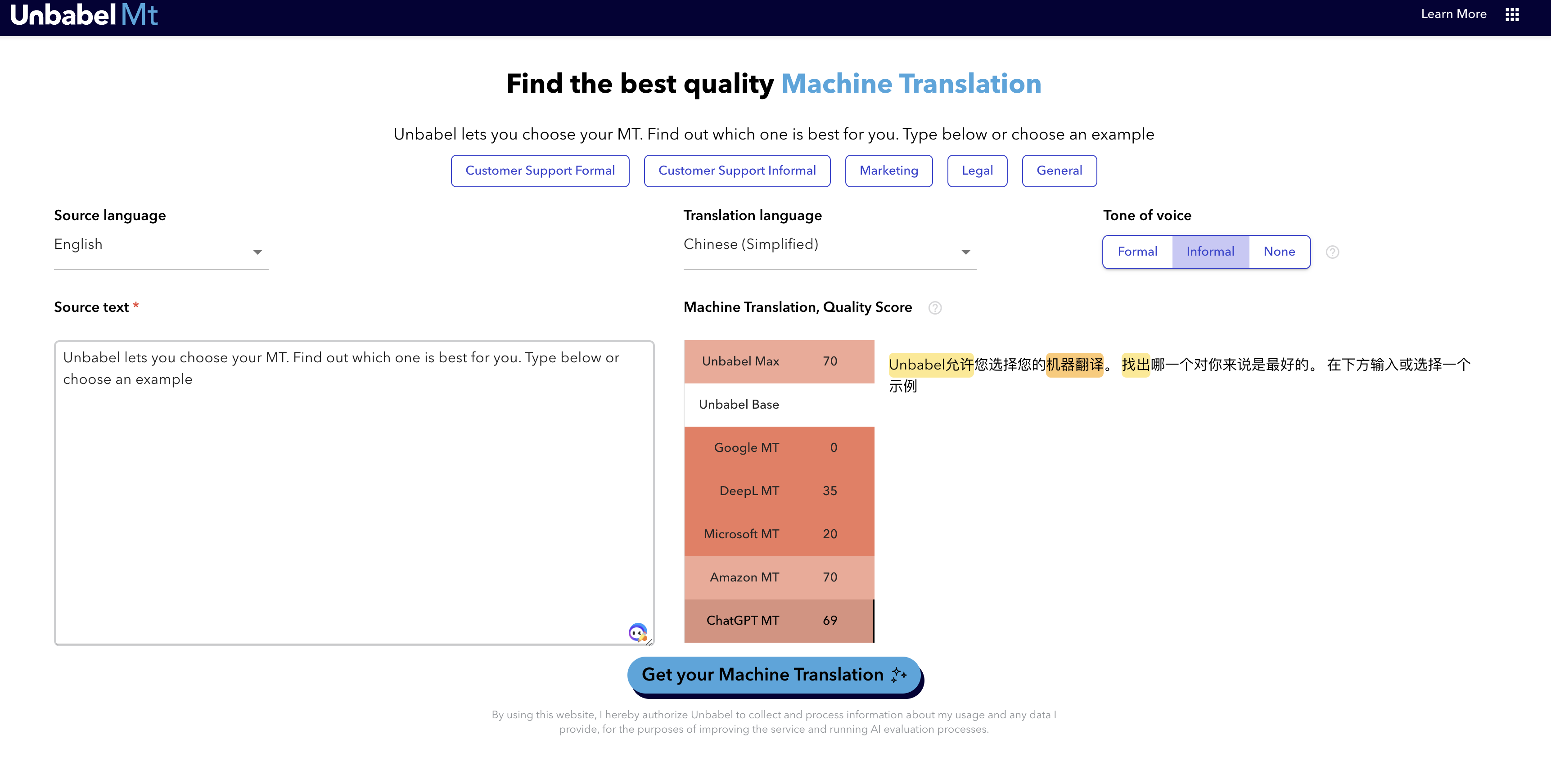
一开始还抱有期望的,一看两个对比,明显还是ChatGPT的效果更好,但是分数却是更低的,不过当然也不能用一个例子就说明一切,还需要更大规模的测试。
系统运行
是骡子是马,还需要拿出来溜溜,于是开始在Colab上跑,不过经常因为下载的时候,没有运行runtime,或者先连着runtime,但是还在模型的下载过程中,Google为了更好的调度资源,又把我的runtime断开了。
pip install --upgrade pip
pip install "unbabel-comet>=2.1.0"
pip install ipywidgets
from huggingface_hub import login
login()
from comet import download_model, load_from_checkpoint
model_path = download_model("Unbabel/wmt23-cometkiwi-da-xxl")
model = load_from_checkpoint(model_path)
data = [
{
"src": "The output signal provides constant sync so the display never glitches.",
"mt": "Das Ausgangssignal bietet eine konstante Synchronisation, so dass die Anzeige nie stört."
},
{
"src": "Kroužek ilustrace je určen všem milovníkům umění ve věku od 10 do 15 let.",
"mt": "Кільце ілюстрації призначене для всіх любителів мистецтва у віці від 10 до 15 років."
},
{
"src": "Mandela then became South Africa's first black president after his African National Congress party won the 1994 election.",
"mt": "その後、1994年の選挙でアフリカ国民会議派が勝利し、南アフリカ初の黒人大統領となった。"
},
{
"src": "I love China.",
"mt": "我爱中国。"
}
]
model_output = model.predict(data, batch_size=8, gpus=1)
print (model_output)
下载模型的时候,要登录Hugging Face,再输入 Token
运行的过程中,内存经常不足,现在大模型时代对玩家的要求也高了,光算力就拦住很多人。每次给别人演示,我用MacBook M2芯片跑起来,大家就很吃惊了,大模型居然可以在本地计算机跑。
其他类似系统
- Flories. Meta 给NLLB开发的评估集。
References:
- Unbabel Wins the QE Shared Task at WMT23: Continuing Excellence in Translation Quality Assessment
- Unbabel Releases its state-of-the-art open source LLM – The First LLM Fine Tuned to Predict Translation Quality