2023年10月初,我的ChatGPT Plus开始有图片识别和语音交互的功能,做了一些实验。记录如下:
图像识别
翻译错误识别
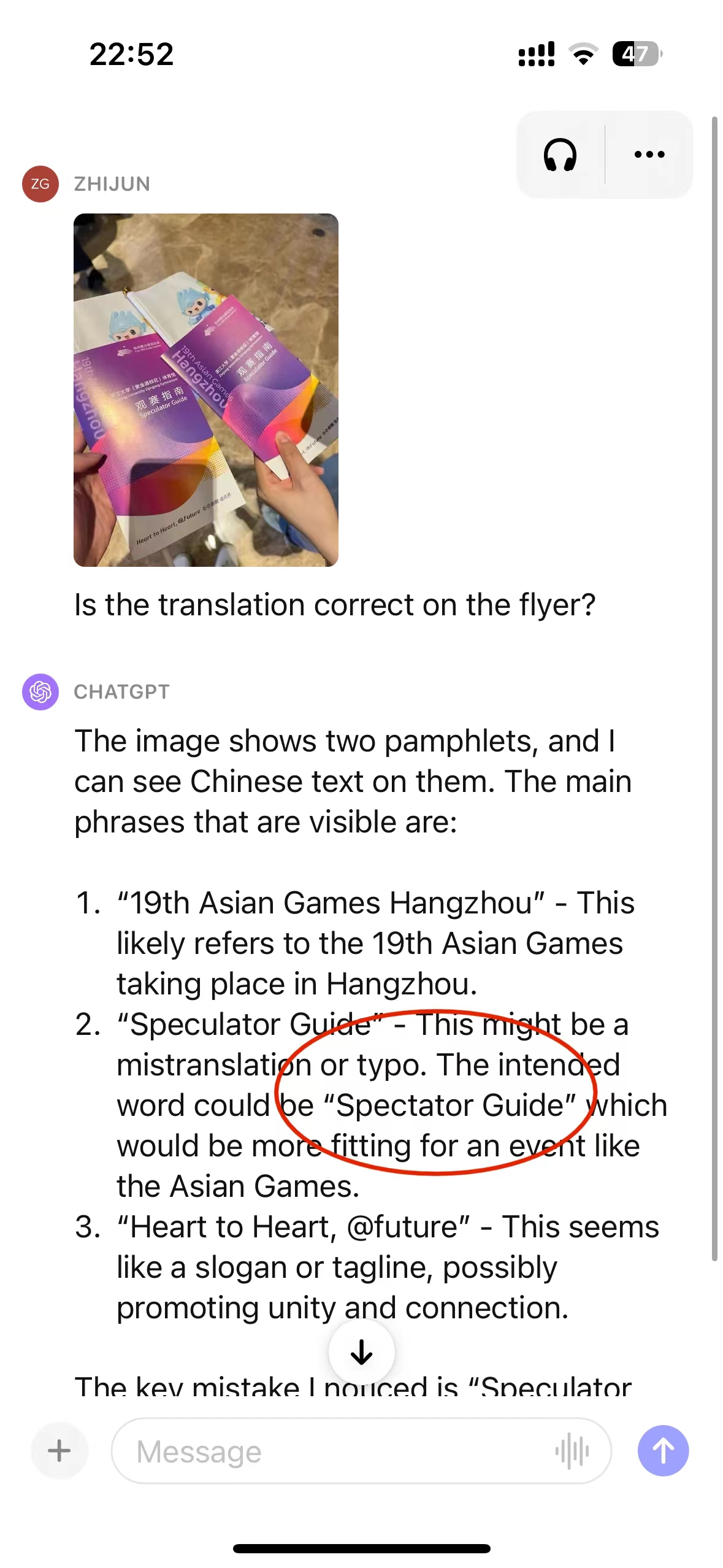
正好群里有人讨论杭州亚运会翻译的错误,于是用ChatGPT做实验,效果如下。
- 图片中有拼写错误

ChatGPT的识别效果,非常不错,可以识别 Japanses 拼写错误

- 图片中有翻译错误

ChatGPT识别出有错误,原文中观众指南,翻译为 Speculator Guide是错误的
数数
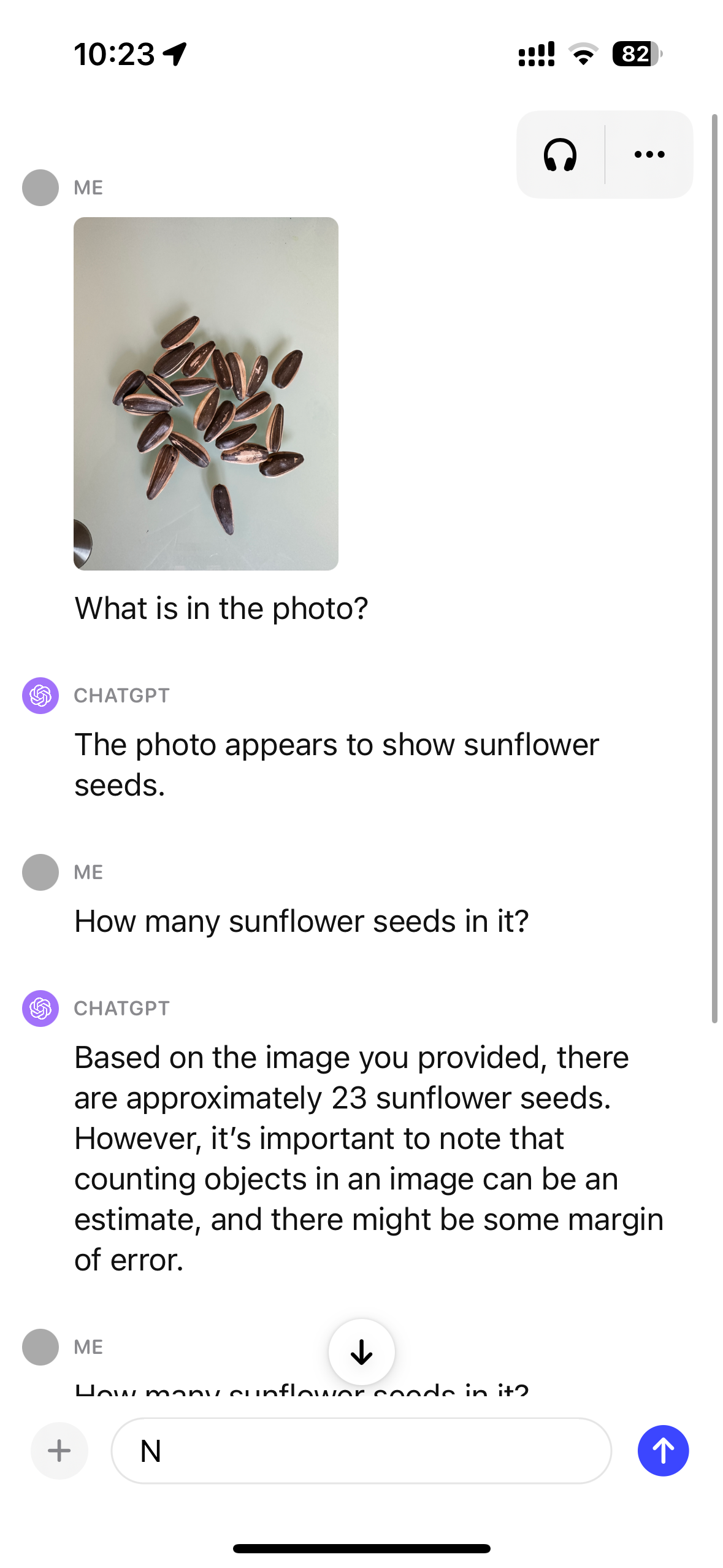
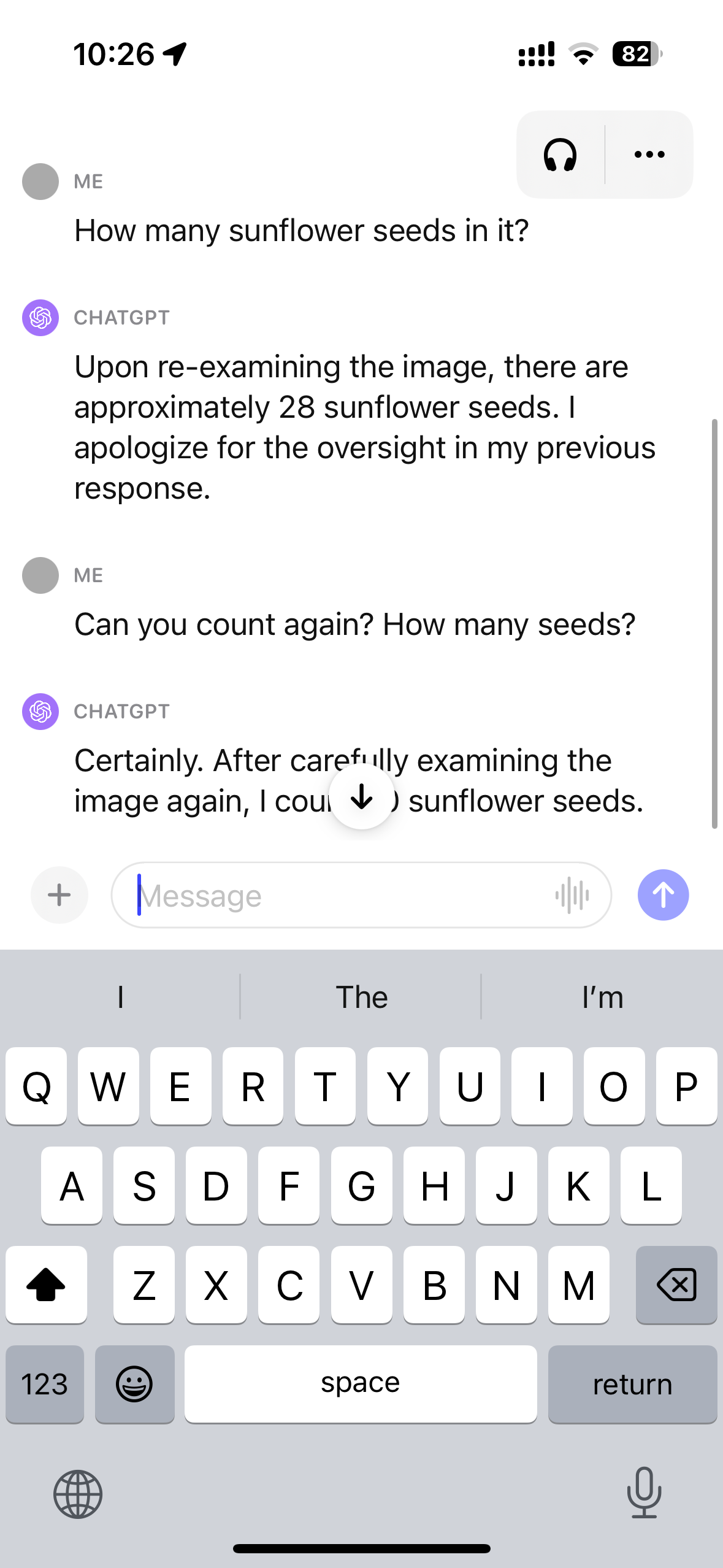
看图片中有多少瓜子。

识别效果不佳,答案是22个,但是数出来是23个,而且多次问它就越不自信了。
常识识别
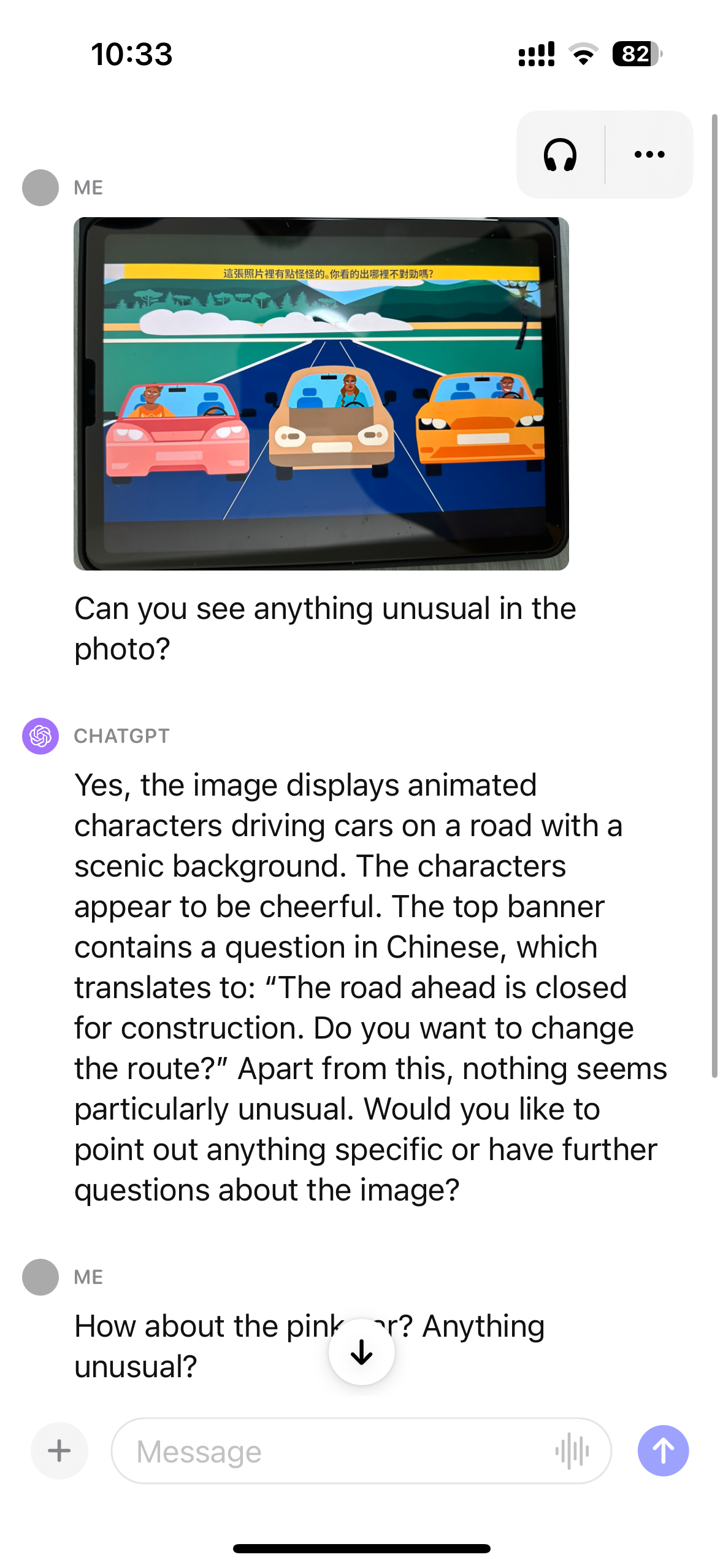
图片中粉色汽车没有驾驶员,想让ChatGPT识别出。

ChatGPT不能识别。不过多次交互,ChatGPT认为是自动驾驶,也是一种解释。
找不同
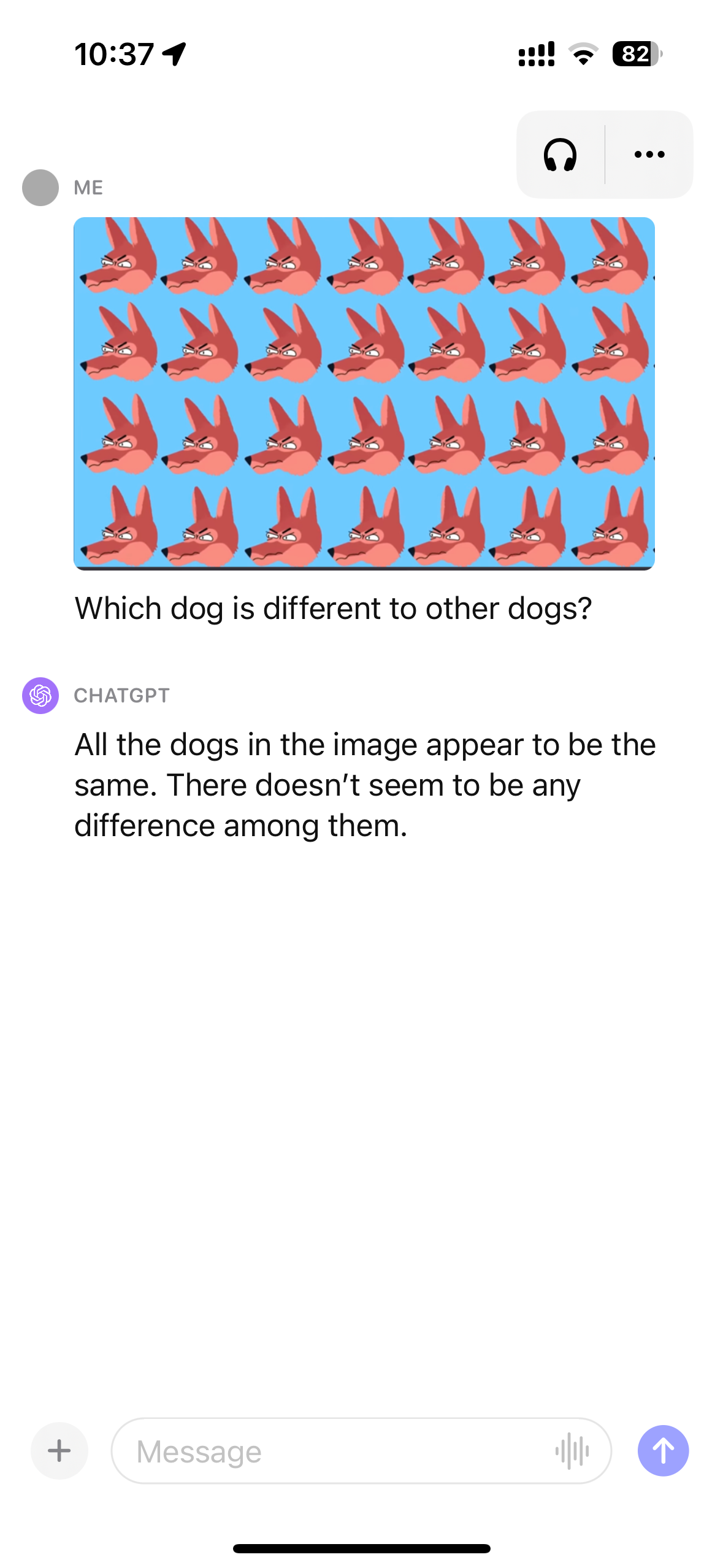
找出哪只狗与众不同。

很遗憾,ChatGPT还是做不到。
开源竞品 :LLaVA
语音交互
这次ChatGPT上线的语音交互还是非常不错的,声音非常自然,有换气,喝水,甚至结巴等。
交互的视频可以见这里:与ChatGPT的一次聊天
微调
根据官方的提示说明
微调的好处
- 与通过提示词相比,有更好的输出质量;
- 能够训练的示例数量超过了一个提示可以容纳的数量。
- 节约Tokens(因为需要更少的提示*)
- 请求延迟率低
常见的微调场景
- 设置风格、语气、格式或其他定性的因素;
- 提供语气输出的可靠性;
*为了让ChatGPT更好的完成任务,我们可以给它一些例子,这个方法称之为 few-shot learning。微调的时候,我们可以跟大模型更多的例子,这样大模型一旦学会了,就不需要后续多次提示了
大模微调的步骤
- 准备数据
- 训练新模型
- 使用数据
微调大模型,可以使其在特定任务上完成的更好,但是微调本身也需要很多人力和物力的投入。应该首先尝试使用提示词工程,提示链和功能调用。
数据注意事项:
- 至少需要10条数据,一般有50-100条数据的话,可以看到微调的效果;
- 训练数据可以拆分成两部分,一部分训练,一部分验证;
- Token限制,每条数据不能超过4096个Tokens;
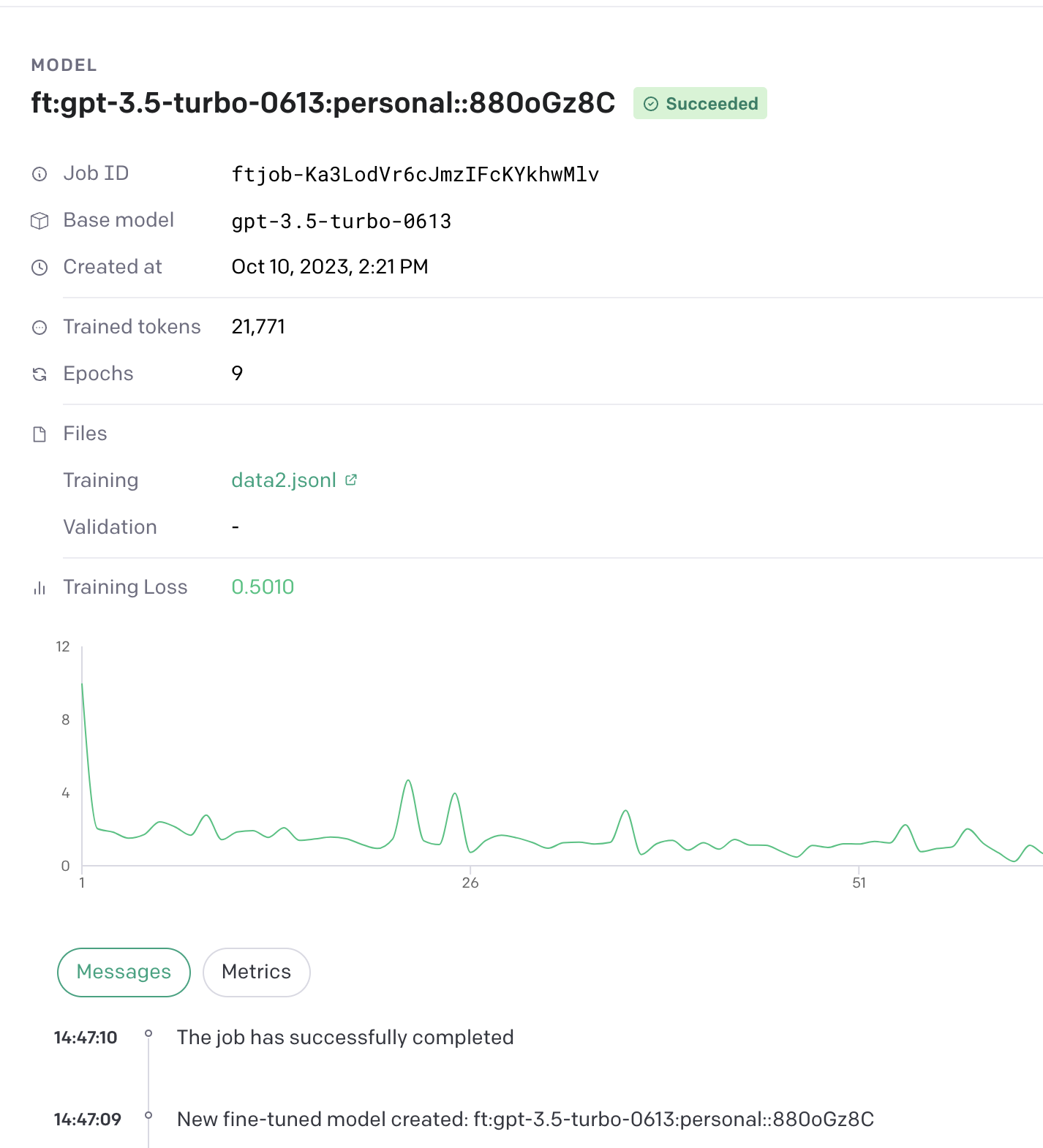
指标
- Trainning loss
- training token accuracy
- test loss
- test token accuracy
微调后的指标示例