基本概念
Prompts & completions
Completions 端点是 API 服务的核心组件。该 API 提供了访问模型的文本输入-输出接口。用户只需提供包含英文文本命令的输入提示(prompt),模型就会生成相应的文本补全(completion)。
以下是一个简单的提示和补全示例:
Prompt:
""" count to 5 in a for loop """Completion:
for i in range(1, 6): print(i)
Tokens (词元)
Azure OpenAI 通过将文本分解为 token(词元) 来处理内容。Token 可以是一个单词,也可以是字符块。例如:
• 单词 “hamburger” 会被分解为 “ham”、“bur” 和 “ger” 这三个 token。
• 而像 “pear” 这样的简短常见单词则是一个单一的 token。
• 许多 token 会以空格开头,例如 “ hello” 和 “ bye”。
在一次请求中,处理的总 token 数量取决于输入的长度、输出的长度以及请求参数的设置。处理的 token 数量还会影响模型的响应延迟和吞吐量。
Transformer
预测下一个词
GPT 工作原理
从自然语言到机器可懂的语言
Tokenization (词元化)
- 单词级别
- 输入:I love NLP!
- 输出:tokens:[“I”, “love”, “NLP”, “!”]
- 子词级别
- 输入:unbelievable
- 输出 tokens:[“un”, “believ”, “able”]
Tokenization 通常保留标点符号、空格或特殊符号,作为单独的 token。
Embedding
Embedding 是一种将高维离散数据(例如单词或句子)映射到低维连续向量空间的技术。它是自然语言处理(NLP)和机器学习中的核心技术,用于将文本等数据转化为模型可以处理的数值形式。
假设以下语料库:”I love NLP”
通过 Word2Vec,生成以下 Embedding:
| 单词 | 向量表示(示例) |
|---|---|
| I | [0.1, -0.2, 0.8] |
| love | [0.5, 0.3, -0.1] |
| NLP | [0.7, -0.4, 0.9] |
提示词
GPT-3、GPT-3.5、GPT-4 和 GPT-4o 是基于提示(prompt-based)的模型
这些模型的交互方式是通过输入文本提示(prompt),模型根据提示生成文本补全(completion)。补全是模型对输入文本的继续生成。
尽管这些模型非常强大,但它们的行为对提示词的敏感度很高。因此,构造提示词(prompt construction)成为一项重要技能。
构造提示的挑战
构造提示并不容易。实际上,提示词的作用是配置模型的权重,以完成期望的任务。但构造提示更像是一门艺术而非科学,往往需要经验和直觉才能设计出成功的提示。
本文的目标是帮助您开始学习这项技能。文章尝试总结适用于所有 GPT 模型的一些通用概念和模式。然而,重要的是要理解每种模型的行为略有不同,因此这些经验可能无法完全适用于所有模型。
在提示末尾重复指令
模型可能会受到最近偏差(recency bias)的影响,在这种情况下,提示末尾的信息可能比提示开头的信息对输出的影响更大。因此,可以尝试在提示末尾重复指令,并评估这对生成的响应是否有影响。
引导输出
这是指在提示的末尾包含一些词语或短语,以使模型的响应符合预期的格式。例如,使用类似 “以下是关键点的项目符号列表:\n- ” 的提示词,可以帮助确保输出以项目符号列表的形式呈现。
| System message | User | Assistant |
|---|---|---|
| You’re an AI assistant that helps people find information. Answer in as few words as possible. | John Smith is married to Lucy Smith. They have five kids, and he works as a software engineer at Microsoft. What search queries should I do to fact-check this? ## One possible search query is: | “John Smith married Lucy Smith five kids software engineer Microsoft” |
添加清晰的语法
在提示中使用清晰的语法(包括标点符号、标题和分隔标记)有助于明确表达意图,并且通常能使生成的输出更容易解析。
在下面的示例中,不同信息来源或步骤之间添加了分隔符(此处为 —),这允许将 — 用作生成的停止条件。此外,部分标题或特殊变量使用大写字母表示,以便区分不同部分。
| System message | User | Assistant |
|---|---|---|
| You’re an AI assistant that helps people find information. | You’ll read a paragraph, and then issue queries to a search engine in order to fact-check it. Also explain the queries. — PARAGRAPH John Smith is married to Lucy Smith. They have five kids, and he works as a software engineer at Microsoft. What search queries should I do to fact-check this? — QUERIES | 1. “John Smith Microsoft” - To check if John Smith is indeed employed at Microsoft. 2. “John Smith Lucy Smith” - To check if John Smith is married to Lucy Smith. 3. “John Smith children” - To check if John Smith has five children. |
指定输出结构
通过提示明确输出的结构,可以显著影响结果的性质和质量。有时,系统消息中的输入内容(如“仅撰写真实信息”或“不要编造信息”)可能不足以有效降低错误率。相反,要求模型在回应中包含引用可以帮助减少错误回答的发生。
如果你指示模型在陈述事实时引用来源,这些陈述更有可能基于真实依据。要求提供引用会让模型在生成回应时需要同时犯下两个错误:第一个是编造的内容,第二个是错误的引用。这意味着生成错误内容的可能性显著降低。此外,引用距离支持文本越近,模型需要预测引用的范围就越短。这表明,文内引用相比于将引用放在内容结尾,更能有效降低虚假内容的生成风险。
类似地,如果你要求模型从段落中提取事实陈述,它可能会提取复合陈述(例如“X 正在做 Y 和 Z”),这类陈述可能更难验证。为避免这种情况,可以指定更明确的输出结构,例如 (实体1, 关系, 实体2)。
| System message | User | Assistant |
|---|---|---|
| You’re an AI assistant that helps people find information. | Cluster the following news headlines into topic categories based on patterns seen within the text. Also mention reasoning behind how these categories were defined. Output format: { “TOPIC_NAME”: “”, “HEADLINES”: [], “REASONING”: “” } Input news headlines: 1. “From books to presentations in 10s with AR + ML” 2. “Demo from 1993 of 32-year-old Yann LeCun showing off the World’s first Convolutional Network for Text Recognition” 3. “First Order Motion Model applied to animate paintings” 4. “Robinhood and other brokers literally blocking purchase of $GME, $NOK, $BB, $AMC; allow sells” 5. “United Airlines stock down over 5% premarket trading” Output: | { “ARTIFICIAL_INTELLIGENCE”: { “HEADLINES”: [ “From books to presentations in 10s with AR + ML”, “Demo from 1993 of 32-year-old Yann LeCun showing off the World’s first Convolutional Network for Text Recognition”, “First Order Motion Model applied to animate paintings” ], “REASONING”: “These headlines are related to artificial intelligence, machine learning, and their applications in various fields.” }, “FINANCIAL_MARKETS”: { “HEADLINES”: [ “Robinhood and other brokers literally blocking purchase of $GME, $NOK, $BB, $AMC; allow sells”, “United Airlines stock down over 5% premarket trading”, “Bitcoin was nearly $20,000 a year ago today” ], “REASONING”: “These headlines are related to financial markets, stocks, cryptocurrencies, and trading platforms.” } } |
最佳实践
-
具体化:尽量减少解释空间,限制操作范围。
-
描述性:使用类比来帮助说明。
-
重复强调:有时需要对模型重复说明。在主要内容之前和之后提供指令,或者使用指令和提示等方式加强说明。
-
顺序重要:向模型提供信息的顺序可能会影响输出效果。例如,将指令放在内容之前(如“总结以下内容……”)或之后(如“总结上述内容……”)可能会导致不同的结果。甚至几个示例的排列顺序也可能影响输出,这被称为最近性偏差。
-
为模型提供“退出路径”:当模型无法完成指定任务时,给它一个替代路径可能会有所帮助。例如,当就某段文本提问时,可以附加说明,例如“如果答案不存在,请回复‘未找到’”。这样可以帮助模型避免生成错误的回应。
微调
模型微调(Fine-Tuning) 是机器学习中的一种方法,指的是在已有的预训练模型基础上,通过少量额外的训练数据对模型进行进一步训练,以适配特定的任务或领域需求。
微调的作用:
- 比仅通过提示词优化(prompt engineering)获得更高质量的结果。
- 能够训练更多示例,超出模型的最大请求上下文限制。
- 节省 Token 消耗,因为提示词更短。
- 尤其是在使用较小模型时,显著降低请求的延迟。
微调通过训练更多样本,通常可以比提示词中容纳的数量更多,从而在大量任务上取得更好的结果。由于微调会调整基础模型的权重以提升特定任务的性能,因此无需在提示词中包含太多示例或说明。这意味着每次 API 调用时发送的文本量更少,处理的 Token 数量也更少,从而可能降低成本并改善请求的响应延迟。
以斯坦福大学推理语料库中文本分类的性能为例,随着微调数据的增加增加,模型在文本分类任务上的表现是增加的。
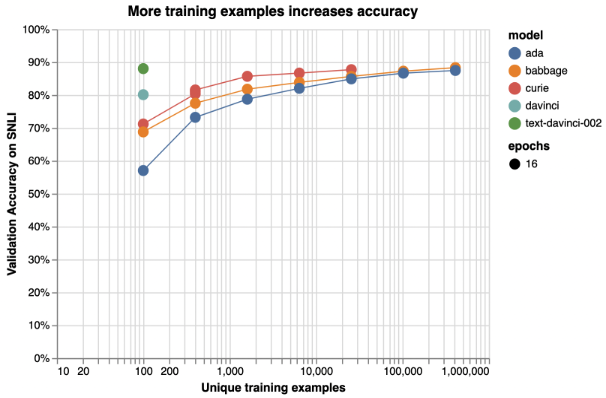
微调之前
微调是一种高级技术,需要专业知识才能正确使用。以下问题可以帮助您评估是否已经为微调做好准备,以及对整个过程的考虑是否充分。您可以利用这些问题指导下一步行动,或识别出其他可能更合适的解决方案。
适合微调的场景:
- 引导模型以特定的自定义风格、语气或格式生成内容。
- 在信息复杂或过长,无法直接放入提示窗口(prompt window)时,使用微调以提高模型的表现。
一些可能表明不适合微调的迹象:
- 没有清晰的微调场景,或者只能模糊地表达“我想让模型更好”。
- 降低成本,微调在某些用例中可能通过缩短提示词或允许使用较小的模型来降低成本,但训练的前期成本较高,您还需要支付托管自定义模型的费用。
- 向模型添加领域外知识,建议先尝试使用检索增强生成(RAG)。
设立基线
微调是一项高级功能,并不是生成式 AI 之旅的起点。在开始微调之前,您应该已经熟悉使用大型语言模型(LLMs)的基本操作。建议先通过提示词优化(Prompt Engineering)和/或检索增强生成(RAG)来评估基础模型的性能,并建立性能基线。
拥有未微调模型的性能基线对于判断微调是否提升了模型性能至关重要。使用低质量数据进行微调可能会使基础模型的性能变差,但如果没有基线数据,就很难发现性能退化的问题。
需要了解提示词和RAG方法的不错,例如:
-
基础模型在边界情况或例外情况下是否表现不佳?
-
基础模型是否无法稳定地输出正确的格式?
-
上下文窗口的容量不足,无法容纳足够多的示例来引导模型?
微调的案例
一位客户希望使用 GPT-3.5-Turbo 将自然语言问题转换为一种特定的、非标准的查询语言。
-
他们在提示词中提供了指导(例如“始终返回 GQL”),并使用 RAG 方法检索数据库架构。
-
然而,模型的语法并不总是正确,并且在边界情况中经常出错。
于是,他们收集了数千个自然语言问题及其数据库对应的查询示例,包括模型先前失败的案例,并使用这些数据对模型进行了微调。通过将微调后的模型与优化后的提示词和检索机制相结合,他们成功将模型输出的准确性提高到了可接受的标准。
微调的方法
LoRA(Low-Rank Adaptation,低秩近似)是一种常见的对模型进行微调的方法,这种方法可以在不显著影响性能的前提下降低模型的复杂度。具体来说,LoRA 通过用低秩矩阵近似原始的高秩矩阵,仅在监督训练阶段微调一小部分重要参数,从而使模型更易管理、更高效。对于用户而言,这种方法使训练速度更快,成本也比其他技术更低。
微调数据
数据要求
- 使用较大的数据集。 数据集的大小取决于任何的复杂度以及模型的种类,通常来说,需要几千到几万条数据。模型越大越能从较少的数据中学习到更多知识。模型还需要足够的知识避免过拟合或者忘记他们之前在预训练阶段已经学到的知识。
- 使用高质量数据集。数据集应统一格式化,已经清楚不完整或不正确的例子。
- 使用有代表性的数据集。微调数据应该具有代表性,例如要微调模型的情感分析能力,需要有不同来源,不同体裁以及不同领域的数据。数据应该可以翻译人类情感的多样性和差压。同时还应该有均衡的正向、负向和中立的示例,避免损害模型的预测能力。
- 使用充分明确的数据。数据集在输入的时候应该包含足够你想在输出中见到的信息。例如,姚微调邮件的输出,泽需要提供清晰和具体的提示词,同时需要定义预期长度、风格以及邮件的语气。
数据格式要求为 JSON Lines (JSONL) ,对于 gpt-35-turbo(所有版本)、gpt-4、gpt-4o 和 gpt-4o-mini,微调数据集必须采用 Chat Completions API 所使用的对话格式。
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Is Xbox better than PlayStation?"}, {"role": "assistant", "content": "I apologize, but I cannot provide personal opinions. My primary job is to assist you with any issues related to your Xbox device. Do you have any Xbox-related issues that need addressing?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "Can I play PC games on my Xbox?"}, {"role": "assistant", "content": "While Xbox consoles don't natively support PC games, they can play an array of Xbox games, many of which are also available on PC. Can I assist you with finding games compatible with your Xbox device?"}]}
{"messages": [{"role": "system", "content": "You are an Xbox customer support agent whose primary goal is to help users with issues they are experiencing with their Xbox devices. You are friendly and concise. You only provide factual answers to queries, and do not provide answers that are not related to Xbox."}, {"role": "user", "content": "I'm having trouble connecting my Xbox to the Wi-Fi."}, {"role": "assistant", "content": "No worries, let's go through the network settings on your Xbox. Can you please tell me what happens when you try to connect it to the Wi-Fi?"}]}
多轮对话的微调格式
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
验证数据
验证数据集(Validation Dataset)是机器学习中的一部分数据集,用于在训练模型的过程中对模型进行评估,以便调整模型的超参数并避免过拟合。它是从原始数据集中划分出来的一部分,既不用于模型训练(训练集),也不用于最终的性能评估(测试集)。
验证数据集的作用
-
模型评估:在训练过程中,通过验证数据集可以评估模型的中间表现,检测模型是否在训练集上过拟合(即在训练数据表现良好,但在未见过的数据上表现差)。
-
调整超参数:通过验证数据集可以选择最优的模型超参数(如学习率、正则化参数、网络结构等)。
-
指导早停(Early Stopping):如果在验证数据集上的性能不再提升,训练可以停止,以防止模型过度训练。
-
选择最佳模型:当训练过程中生成多个模型时,验证数据集可以帮助选择在未知数据上表现最佳的模型。
为什么需要验证?
-
检测过拟合与欠拟合:
-
如果模型在训练集上表现很好,但在验证数据集上表现差,这通常表明模型过拟合。
-
验证数据可以提供模型在未见过的数据上的性能反馈,帮助检测模型是否适合泛化。
-
-
确保模型性能稳定:验证数据集可以帮助判断模型是否具有稳定的性能,而不仅仅是对特定训练数据的“记忆”。
-
优化模型的设计:通过验证,可以在训练中及时调整模型的架构或策略(如激活函数、优化算法等)。
检查点(Checkpoints
每当一个训练周期(epoch)完成时,系统会生成一个检查点。检查点是模型的一个完整功能版本,可以用于部署,也可以作为后续微调任务的目标模型。
检查点特别有用,因为它们可以在模型发生过拟合之前提供模型的快照。当微调任务完成后,您将拥有最近的三个模型版本,这些版本都可以用于部署。
作用:
- 保存模型中间状态:在每个训练周期(epoch)完成后,模型会保存当前的权重和配置,这些数据构成一个检查点。它表示模型在这一时刻的表现。
- 防止训练过程中的损失:如果训练过程中出现中断(如硬件故障或意外停止),可以通过加载最近的检查点来恢复训练,而无需从头开始。
- 评估模型性能:检查点可以用于评估模型在不同阶段的表现,例如检测是否已经出现过拟合。当模型在训练集上表现越来越好,但在验证集上性能开始下降时,通常意味着模型出现了过拟合。检查点保存了模型在每个阶段的状态,可以帮助回滚到未过拟合的最佳模型版本。检查点常与早停机制结合使用,早停会在验证性能不再提升时终止训练,并选择对应的检查点作为最终模型。
- 选择最佳模型:通过检查点记录模型在验证集上的性能,可以选择性能最佳的版本进行部署,而不一定使用训练结束时的版本。
通常在每个 epoch 结束时生成一个检查点,有些情况下,也可以在训练的特定间隔(如每隔 N 步)生成检查点。
检查点通常包含以下内容:
-
模型的权重(Weights/Parameters)。
-
优化器状态(Optimizer State),用于恢复训练进度。
-
训练的超参数配置(如学习率)。
-
当前的训练步数(Step Count)或周期数(Epoch Count)。
检查点的管理
-
存储限制: 每次保存检查点都会占用存储空间,因此一般只保留最近几次的检查点(如最后 3 个),或者根据验证性能筛选出表现最好的版本。
-
命名与版本控制:检查点通常会以训练步数或验证集损失命名,例如 model_epoch_10_loss_0.25.ckpt,以便于查找最佳版本。
假设在微调 GPT-4 模型: • 每训练一个周期生成一个检查点(如 epoch_1.ckpt, epoch_2.ckpt)。 • 在第 5 个周期后,发现验证集性能下降(过拟合)。 • 可以选择第 4 个周期的检查点作为最终模型,避免使用过拟合的模型。
### 微调参数
| 名称 | 类型 | 描述 |
|---|---|---|
| batch_size | 整数 | 用于训练的批量大小。批量大小指的是在一次前向和反向传播中使用的训练样本数量。一般来说,对于较大的数据集,较大的批量大小效果更好。此属性的默认值和最大值取决于具体的基础模型。较大的批量大小意味着模型参数更新的频率较低,但方差较小。 |
| learning_rate_multiplier | 数值 | 用于训练的学习率倍增器。微调学习率是预训练中使用的原始学习率与该值的乘积。较大的学习率通常在较大的批量大小中表现更好。建议尝试在 0.02 到 0.2 的范围内调整以找到最佳效果。较小的学习率可能有助于避免过拟合。 |
| n_epochs | 整数 | 模型训练的轮次。一个轮次指的是完整遍历一次训练数据集的过程。 |
| seed | 整数 | 用于控制作业可重复性的种子。使用相同的种子和作业参数应产生相同的结果,但在极少情况下可能会有差异。如果未指定种子,系统会自动为你生成一个。 |
微调其他模型的工具
术语
参考来源:
- When to use Azure OpenAI fine-tuning
- Customize a model with fine-tuning
- Azure OpenAI GPT-4o-mini fine-tuning tutorial
- Getting started with LLM fine-tuning