Project Source
Commissioned by: National Language Commission
Principal Investigator: Zhijun Gao
Project Duration: January 1, 2026 - December 31, 2026
Project Overview
Research Background
Existing research on Traditional Chinese Medicine (TCM) terminology primarily aims for rigor and accuracy, serving doctors and professional practitioners, with emphasis on academic consistency and standardization of concepts. However, in the practice of international dissemination of TCM culture, an increasing amount of content is presented in the form of audiovisual programs such as documentaries, interviews, popular science programs, and short videos, with audiences primarily consisting of non-professional users.
In this communication context, directly adopting highly specialized terminology systems tends to increase comprehension costs and weaken communication effectiveness, which is particularly prominent in cross-linguistic and cross-cultural communication. How to select multilingual terminology expressions that better align with public understanding and audiovisual communication characteristics without distorting core TCM concepts has become a key issue in the current international dissemination of TCM. This project explores methods for constructing multilingual TCM terminology for audiovisual programs in response to this practical need.
Research Plan
-
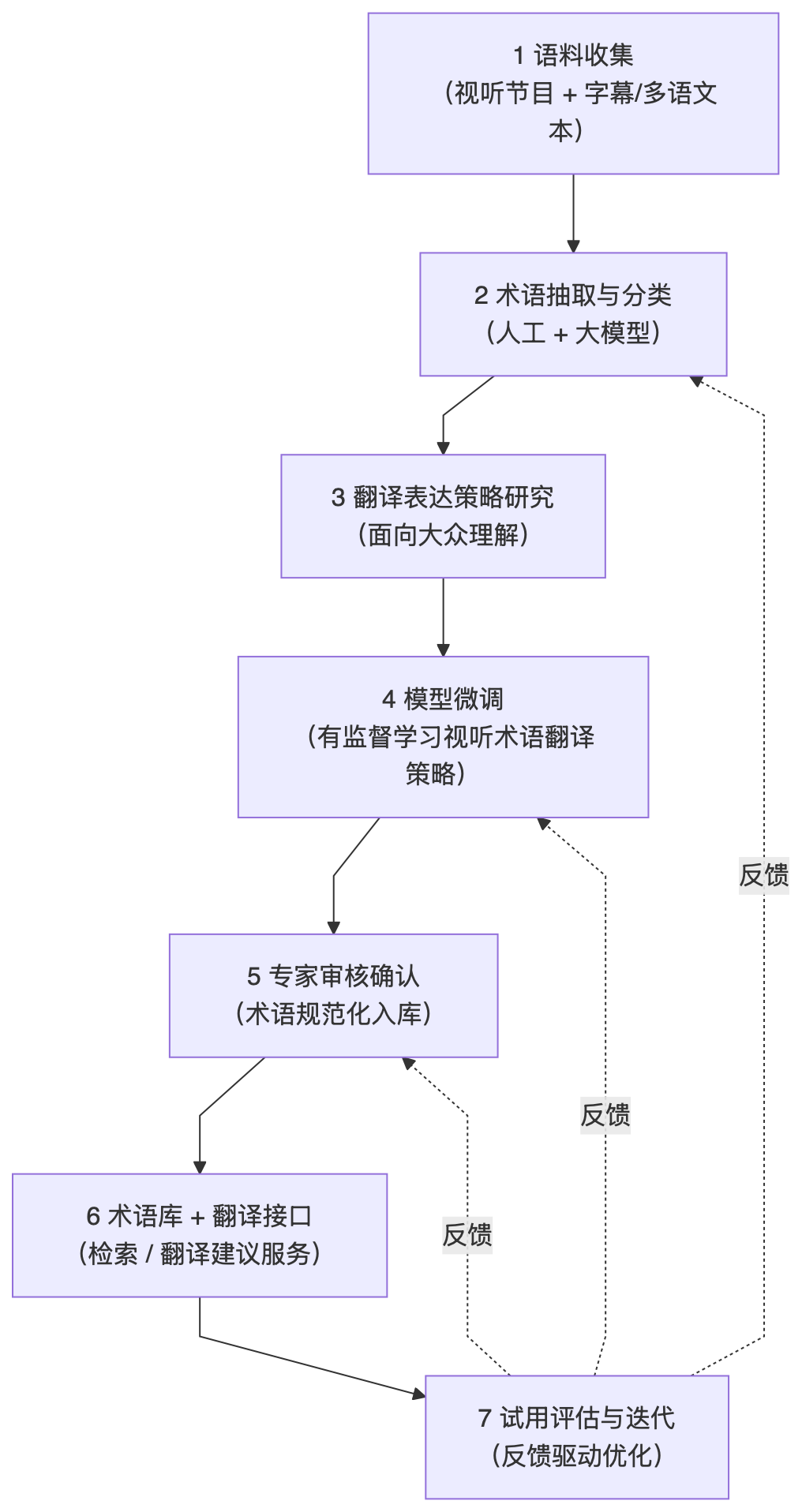
Collect TCM cultural audiovisual corpora. Systematically collect audiovisual materials related to TCM, including documentaries, interview programs, and popular science videos; organize their subtitles and multilingual texts to build a research corpus.
-
Identification and classification of TCM terminology in audiovisual contexts. Combining manual analysis with large language models, extract and classify TCM terminology from the corpus, distinguishing between professional terms, semi-professional terms, and popular expressions.
-
Research on multilingual terminology expressions for public understanding. Investigate terminology translations and expression strategies suitable for audiovisual communication across different linguistic and cultural backgrounds, addressing the balance between literal translation, free translation, and explanatory expressions.
-
Fine-tuning large language models and learning terminology translation strategies based on audiovisual corpora. Using the previously collected and annotated audiovisual corpora, conduct supervised fine-tuning of large language models to enable them to learn and internalize TCM terminology translation strategies in audiovisual communication contexts, including terminology selection, expression simplification, and contextual adaptation capabilities.
-
Expert verification and terminology standardization for database entry Organize domain experts to manually review and confirm the terminology translations and candidate expressions generated by the model, complete standardization processing (concept boundaries, recommended translations, applicable contexts, aliases/prohibited translations, etc.), and create sustainably maintainable terminology entries.
-
Terminology database construction and translation API services Build the expert-confirmed terminology entries into a multilingual terminology database, and provide translation interfaces for experts (such as API/retrieval and suggestion services): after experts input terminology or context fragments, the system returns translation suggestions, candidates, and usage tips based on the terminology database and fine-tuned model, supporting rapid decision-making in subtitling/narration and other audiovisual scenarios.
-
Application validation and iterative optimization Trial the terminology database and translation interface in typical program segments or actual production workflows, collect expert feedback and real usage data for terminology entry supplementation and continuous model/strategy iteration.
Expected Outcomes
- Multilingual terminology database for TCM cultural audiovisual programs
- Research on building a multilingual terminology database for TCM cultural audiovisual programs based on large language models